Routing to namespaces
I was interested to know how a buffer (skb) is “routed” to a specific namespace or process .
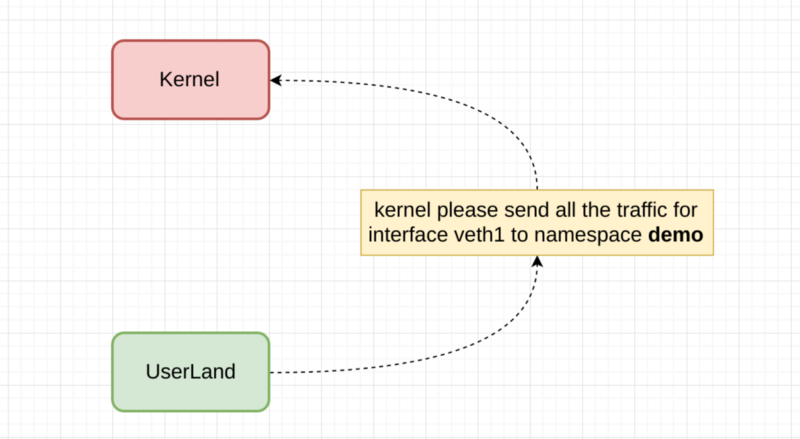
Simple as that , i want to know the mechanism in which userland tells the kernel to send data to a specific namespace /interface.
So what i’ve found is that the kernel has a specific interface created around 2.4 that is specific for this use . AF_NETLINK , you might find it familiar to AF_UNIX or AF_INET , and it is cause it is built on top of bsd sockets architecture , so it uses methods such as bind() listen() accept() etc.
So here it goes, first i will strace the userland commands that create network namespaces (ip route2):
strace ip netns add demo -e trace=network
This creates a network namespace and will unshare() from the parent , and a snippet of the result is:

So you can see something is happening , for some reason ip route created a socket of a specific type (NETLINK) and is sending some data (configuration data , such as routing ) to the kernel supposedly.
After that the unshare happens: (notice the CLONE_NEWNET)

So far in theory we have a new network namespace , which we can check doing :
ip netns show

Looking good , now we need to create a peer or veths and add one of them to the namespace , you probably seen veths before , they’re virtual ethernet device and most time come in pairs , it is like a sort of frame forwarding device , any frames you insert in veth0 will get to veth1 for example.
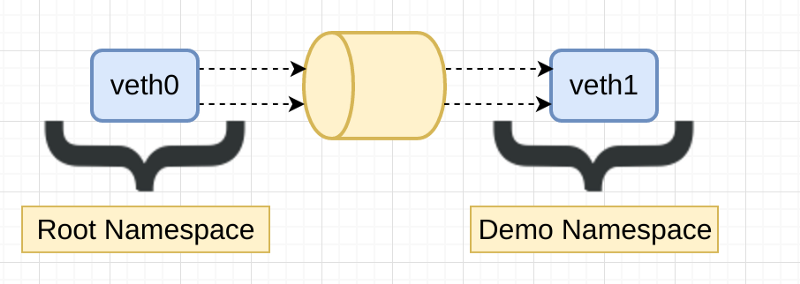
Let’s create a pair of Veths and add one of them to the demo namespace
ip link add veth0 type veth peer name veth1
and now attach veth1 to demo
ip link set veth1 netns demo
Great , none of these interfaces have an ip address yet so nothing will really work yet , but how can we sort of “tcpdump” NETLINK traffic , is it even possible?
In theory we should see a AF_NETLINK message from ip route to the kernel saying “hey all that the traffic comming to veth1 , should be also go to this namespace”
As far as i know this can’t be done with tcpdump but ip route has a monitor function and this is what we get:
ip monitor all
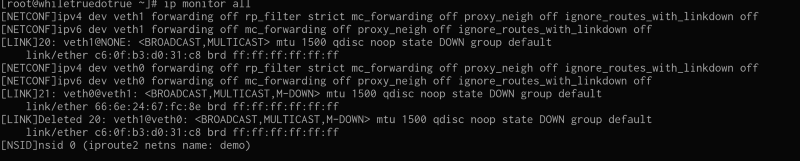
I think the part that seems clear to me is what happens after “ip link set veth1 netns demo”

The implementation of netlink (net/netlink/af_netlink.c) is fully aware of user namespaces .
The question that remain is now that the kernel knows that a given traffic has to be “routed” to a specific namespace (or a specific copy of the network stack) , how does it work from there ? well i don’t know yet but i’ll try to find out.